





Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Great article!! Keep them coming
Thanks, glad you enjoyed it!
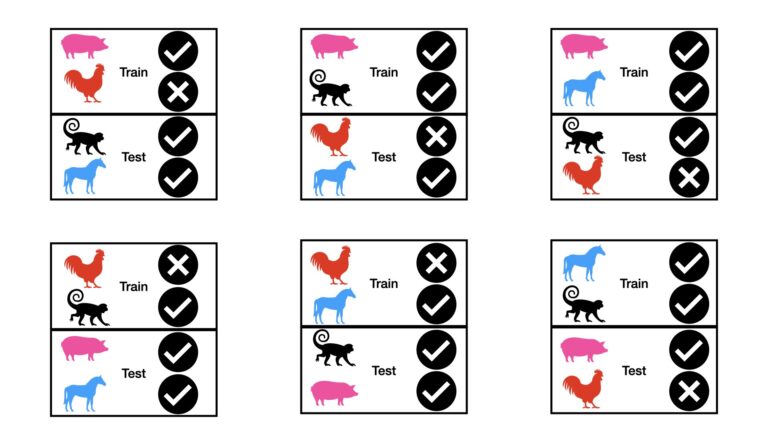
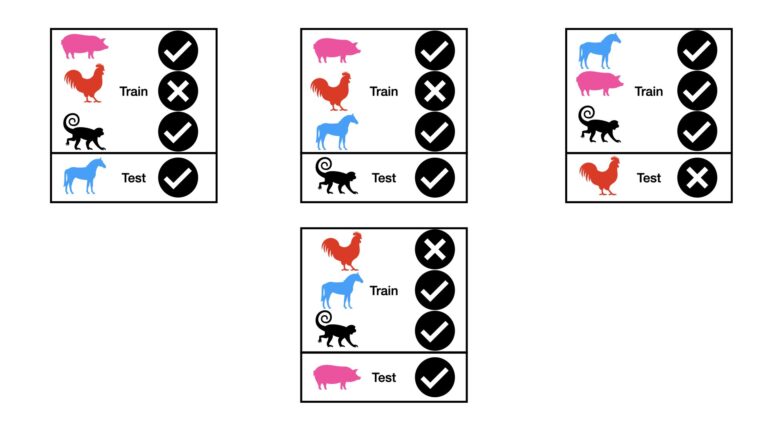
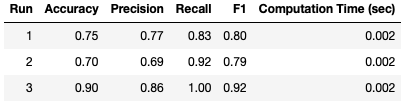
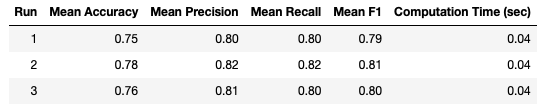
[…] as to which method we use, it is best practice to evaluate each hyperparameter configuration with Cross-Validation. More specifically, it is typical to make use of K-Fold Cross-Validation to determine the […]
[…] via the ordering in the pipeline. In addition, pipelines facilitate a data scientist in performing cross-validation over an entire modelling project that is composed of various steps (pre-processing, modelling, […]
[…] entire Pyspark data processing sequences. In addition, pipelines enable data scientists to perform cross-validation over an entire modeling project that is composed of various steps (pre-processing, modeling, […]
Clear and practical this guide demystifies cross-validation with helpful explanations and hands-on Python examples. Encouraging learning through implementation