Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
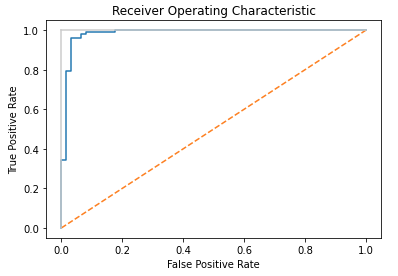
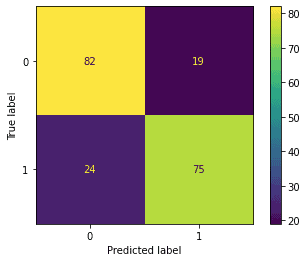
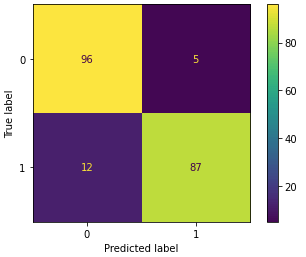
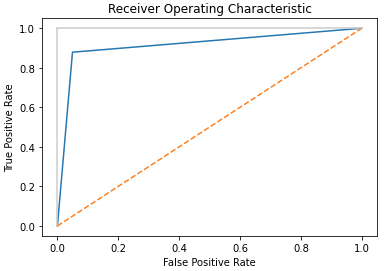
[…] Now let’s test the performance of our pipeline, using standard measures of performance for a classifier: […]
[…] approaches for evaluating a classifier involve metrics such as accuracy, precision, recall, and F1. In addition to these, another powerful approach is to compute the Area Under the Curve (AUC). Here […]