A Sklearn Pipeline is a Python object composed of a set of transformation classes, that can be executed in sequence to process data. Pipelines enable a programmer to organise a project as a set of components, that can then be orchestrated to work together, via the ordering in the pipeline. In addition, pipelines facilitate a data scientist in performing cross-validation over an entire modelling project that is composed of various steps (pre-processing, modelling, post-processing).
Table of Contents

What is a Sklearn Pipeline? 2 Simple Examples in Python – image by author
What is a Sklearn Pipeline?
A pipeline is a software architecture that consists of executing various processing steps in sequence, on the available data. Each processing step can be termed as a stage, or step, in the pipeline. There are various ways to make use of pipelines when organising a project. For instance a single pipeline, with steps performing pre-processing, modelling, and post-processing, can run an entire machine learning application. Alternatively, it is possible to build individual pipelines to perform preprocessing, modelling, and post-processing separately for more complex projects. The exact way you implement a pipeline in your project is up to you!
For a newly created sklearn pipeline, the various steps will consist of one of the following types of objects:
- Transformer: a scikit-learn transformer takes in data, and return a modified form of the data. All intermediate steps in the pipeline are of this type. It has both fit and transform methods.
- Estimator: a scikit-learn estimator takes in data, and returns a Transformer. The final step in the pipeline is permitted to be of this type. It is required to have at least a fit method.
After it is assembled, the pipeline can be treated like any other scikit-learn model. We can train it, and then use the trained pipeline to produce model output and test performance.
Benefits of Using Sklearn Pipelines?
Structuring our code into pipelines helps to facilitate many benefits. These consist of:
- Modular Code: each stage can be designed to operate independently and to fulfil a specific task. This helps to create a reusable code base.
- Understanding the Code: looking at the pipeline will quickly reveal what actions are being done by the software, and in what order. This helps with quickly gaining a holistic picture of what the code does.
- Enhance Automation: a pipeline is an ideal structure for organising a production quality code-base for ETL (Extraction-Transform-Load) operations. The expectation is that the system will operate independently over some extended period of time.
- Facilitate Scalability: stages can be added or removed as is needed by the application.
Sklearn Pipeline Examples in Python
Let’s now make this discussion more tangible, by diving into two worked examples in Python! We can start by importing all the required packages:
# imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.metrics import (accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
ConfusionMatrixDisplay)Python Example #1: Building a Standard Pipeline
Let’s construct a simple dataset we can use, and then build a pipeline with a series of transformers and a final estimator we imported from scikit-learn:
# build a toy dataset with numeric predictor features
X,y = make_classification(n_samples=10000,
n_features=20,
n_informative=10,
n_redundant=5,
shift=10,
scale=5,
random_state=42)
# do train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# assemble a pipeline
pipe = Pipeline(steps=[('scaler', StandardScaler()),
('pca', PCA(n_components=10)),
('lr', LogisticRegression())])I’m making use of make_classification to generate a dataset of 10000 samples, with a total of 20 predictive features. Of these features, only 10 are informative, with another 5 being redundant. By default, two class labels will be produced. A train-test split is subsequently performed, where 20% of the data is held out for testing.
The pipeline is then constructed, with a total of 3 steps. A description for the logic inside this pipeline is provided below:
- First, the predictive features are scaled using StandardScaler, such that each feature has a mean of 0.0 and standard deviation of 1.0.
- Next, to extract out the useful information from the predictive features, I apply PCA to the output from step 1. Since there are only 10 informative features in our data, I extract out only the top 10 principal components.
- Finally, I perform logistic regression to the output from step 2, to yield a predictive model for our data.
Now let’s test the performance of our pipeline, using standard measures of performance for a classifier:
# train the pipeline and test the result
pipe.fit(X_train, y_train)
# produce predictions
y_pred = pipe.predict(X_test)
# display resulting metrics
print(f"accuracy: {accuracy_score(y_test,y_pred):.2f}")
print(f"precision: {precision_score(y_test,y_pred):.2f}")
print(f"recall: {recall_score(y_test,y_pred):.2f}")
print(f"f1: {f1_score(y_test,y_pred):.2f}")accuracy: 0.81 precision: 0.81 recall: 0.78 f1: 0.80
# display a confusion matrix
cm = confusion_matrix(y_test, y_pred, labels=pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=pipe.classes_)
disp.plot()
plt.show()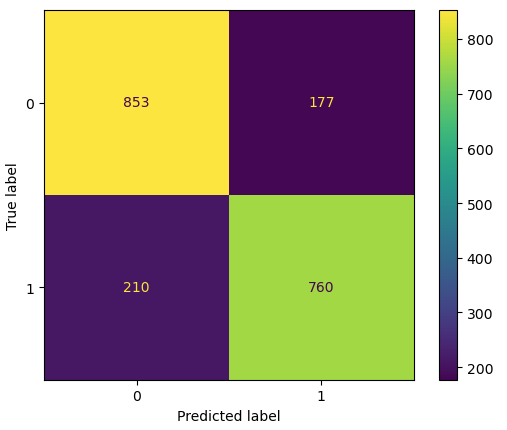
Figure 1: Confusion matrix for the 3-step pipeline.
It is apparent that the pipeline is functioning correctly, and yields reasonable results.
Python Example #2: Writing a Custom Transformer
Let’s add an additional predictive feature to the dataset generated in example #1. However, this feature will be categorical in nature. To accomplish this, I will store the predictive features inside a pandas dataframe:
# create new categorical column & add it to the list of predictors
dfX = pd.DataFrame(X, columns = [f"col_{i+1}" for i in range(X.shape[1])])
dfX[f"col_{X.shape[1]+1}"] = np.where(y == 0, "red", "blue").reshape(-1,1)
dfX.head(5)
Our new feature is listed under column col_21 on the right. As this feature is categorical, we’ll need to create a new transformer that can convert this into numerical values. Let’s implement this transformer below:
class NewTransformer(BaseEstimator, TransformerMixin):
"""
Class to handle revised dataset with a categorical feature with 2 unique values
"""
def __init__(self) -> None:
self.categorical_cols = []
def fit(self, dfX: pd.DataFrame, y=None) -> None:
"""
Fit method for our new transformer.
Inputs:
dfX -> pandas dataframe of predictor features
y -> numpy array of labels (not used)
"""
for col in dfX.select_dtypes(['object']):
self.categorical_cols.append(col)
return self
def transform(self, dfX: pd.DataFrame) -> np.array:
"""
Transform method for our new transformer
Input:
dfX -> pandas dataframe of predictor features
Output:
numpy array of transformed values
"""
return pd.get_dummies(dfX,
columns=self.categorical_cols,
drop_first=True).valuesNow let’s repeat the analysis done earlier, but with an additional stage in our pipeline to include the new transformer:
# do train-test split
X_train, X_test, y_train, y_test = train_test_split(dfX, y, test_size=0.2, random_state=42)
# assemble a pipeline
pipe = Pipeline(steps=[('ohe', NewTransformer()),
('scaler', StandardScaler()),
('pca', PCA(n_components=10)),
('lr', LogisticRegression())])
# train the pipeline and test the result
pipe.fit(X_train, y_train)
# produce predictions
y_pred = pipe.predict(X_test)
# display resulting metrics
print(f"accuracy: {accuracy_score(y_test,y_pred):.2f}")
print(f"precision: {precision_score(y_test,y_pred):.2f}")
print(f"recall: {recall_score(y_test,y_pred):.2f}")
print(f"f1: {f1_score(y_test,y_pred):.2f}")accuracy: 0.93 precision: 0.93 recall: 0.93 f1: 0.93
# display a confusion matrix
cm = confusion_matrix(y_test, y_pred, labels=pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=pipe.classes_)
disp.plot()
plt.show()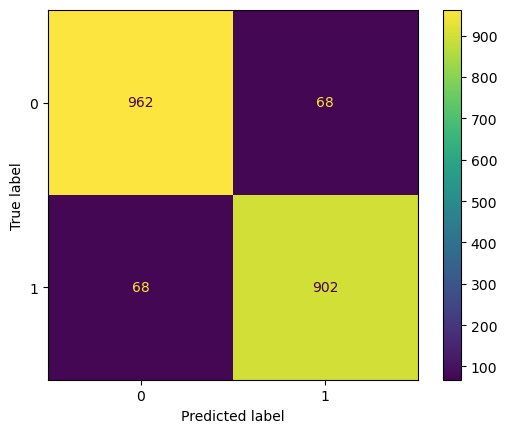
Figure 2: Confusion matrix for the 4-step pipeline
We can see that the inclusion of the extra feature has dramatically improved the performance of our classifier. This shouldn’t be too surprising: the categorical feature maps 1-to-1 to our label!
Final Remarks
In this post you have learned:
- What is a sklearn pipeline.
- Why it can be beneficial to use them in your machine learning project.
- How to implement a sklearn pipeline using transformers and estimators available from scikit-learn.
- How to build a custom transformer for use inside a sklearn pipeline.
I hope you enjoyed this article, and gained some value from it. If you would like to take a closer look at the code presented here, please take a look at my GitHub. If you have any questions or suggestions, please feel free to add a comment below. Your input is greatly appreciated.
Related Posts
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.