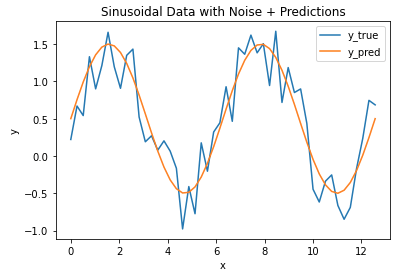
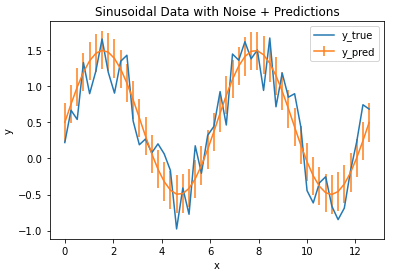
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
wow great article
Glad you enjoyed it!
[…] strong resilience to outliers. This is in contrast to other metrics previous discussed, such as the Mean Absolute Error or Mean Squared […]