In this post we’ll cover the Mean Squared Error (MSE), arguably one of the most popular error metrics for regression analysis. The MSE is expressed as:
MSE = \frac{1}{N}\sum_i^N(\hat{y}_i-y_i)^2 (1)
where \hat{y}_i are the model output and y_i are the true values. The summation is performed over N individual data points available in our sample.
The advantage of the MSE is that it is easily differentiated, making it ideal for optimisation analysis. In addition, we can interpret the MSE in terms of the bias and variance in the model. We can see this is the case by expressing (1) in terms of expected values, and then expanding the squared difference:
MSE = E[(\hat{y}-y)^2]
= E[\hat{y}^2 + y^2 – 2\hat{y}y]
We can now add positive and negative E(\hat{y})^2 terms, and make use of our definitions of bias and variance:
= E(\hat{y}^2) – E(\hat{y})^2 + E(\hat{y})^2 + y^2 – 2yE(\hat{y})
= Var(\hat{y}) + E(\hat{y})^2 – 2yE(\hat{y}) + y^2
= Var(\hat{y}) + E[\hat{y} – y]^2
= Var(\hat{y}) + Bias^2(\hat{y})
One complication of using the MSE is the fact that this error metric is expressed in termed of squared units. To express the error in terms of the units of y and \hat{y}, we can compute the Root Mean Squared Error (RMSE):
RMSE = \sqrt{MSE} (2)
In addition, the MSE tends to be much more sensitive the outliers when compared to other metrics, such as the mean absolute error or making use of the median.
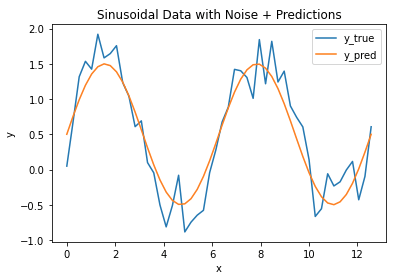
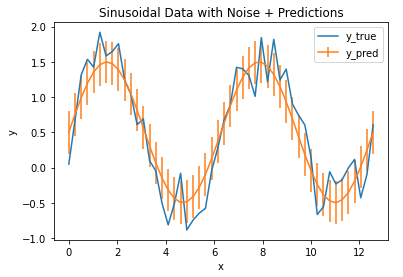
[…] The Median Absolute Error is a metric that can be used to quantify a regression models performance. This measure is slightly more difficult to interpret for a non-technical audience. However, the main benefit of using this quantity is its strong resilience to outliers. This is in contrast to other metrics previous discussed, such as the Mean Absolute Error or Mean Squared Error. […]