Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Congrats for your web page Mike, and thank you for recall me linear regression and least squares estimation method.
Thank you Efren!
Thanks! Great information
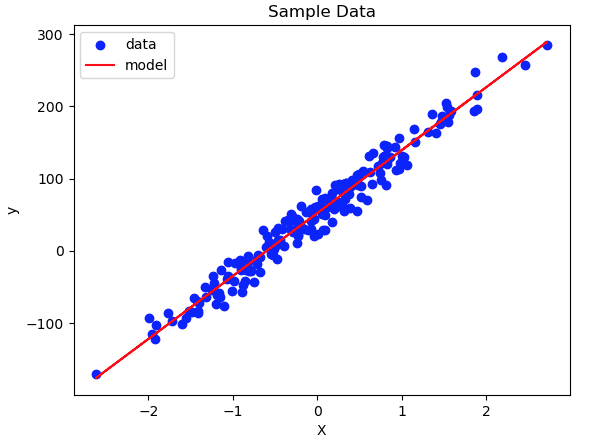
[…] In this example, we’ll build the code required to prepare a regression dataset, and fit a Linear Regression model. Let’s start by importing all the necessary […]
[…] will check how the explainability results different between two very different modeling algorithms: Linear Regression and Random […]