In this post, we will cover PageRank, a popular unsupervised algorithm originally designed for ranking websites. I will first describe what problem this algorithm aims to solve, and then cover its mathematical description. Finally, we’ll implement this algorithm into Python, and verify everything works. All code presented here can also be downloaded from my Github.
Table of Contents

Learn the PageRank Algorithm with 1 Simple Example – image by author
What is PageRank?
PageRank was originally developed at Google by Larry Page and Sergey Brin. This algorithm is famous for being the original basis for the Google Search Engine.
The original problem PageRank aims to solve, is how to order webpages from a search result? The key assumption made is: more popular/relevant webpages will tend to have more links to other webpages. More specifically, the most relevant pages will tend to have the largest number of incoming links from other webpages. PageRank therefore assigns a score to each webpage, based on its interconnectivity with other webpages. These scores (or ranks) can be used by a search engine to sort the resulting websites, in order of most-relevant to least.
Fundamentally, PageRank can be categorized as a Graph Algorithm, since the relation of webpages on the internet can be modeled as a directed graph. In this way, the nodes in the graph represent webpages, and edges indicate links between said pages. Let’s take a peek at a small example:
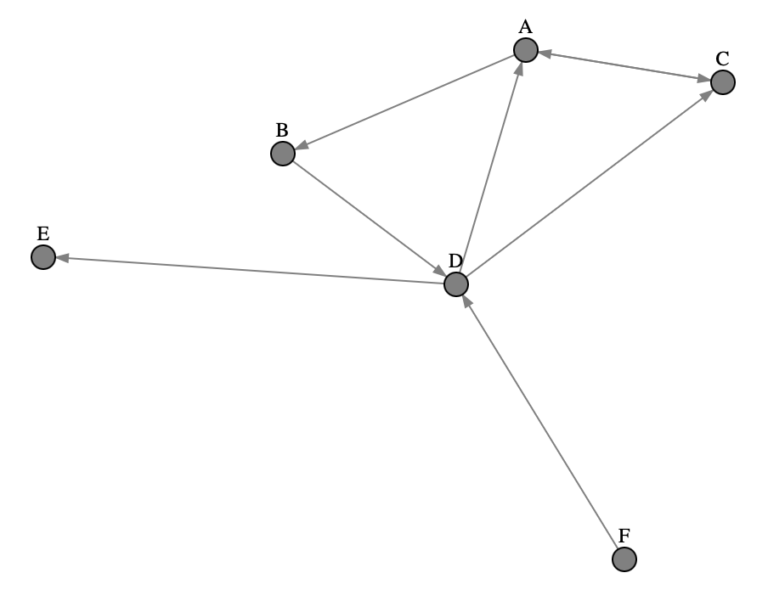
Figure 1: Illustration of a simple directed graph consisting of 6 nodes.
The illustration above shows the relations between 6 different webpages: A, B, C, D, E, and F. Taking a quick look at Figure 1, it is evident that nodes A, C, and D have the largest number of incoming links. As such it wouldn’t be too surprising that these webpages are interpreted as highly popular. Conversely, node F has no incoming links, and as such it shouldn’t be rated too highly.
It is important to note that although PageRank was originally developed for the task of web search, it is not limited to this. The PageRank algorithm can be applied to any problem that can be modeled as a graph, where the relevance/ranking of nodes is useful to know.
Mathematically Describe the PageRank Algorithm
Let’s now work to add a formal procedure to the ideas mentioned above. We can begin simply, and then work to develop a complete model.
First Attempt: Simplified Approach
To gain some intuition, let’s first work through a basic version of the algorithm. We will create an iterative procedure, that will function as follows:
- initialize all nodes in the graph to have the same rank value = 1/(\text{number of nodes in the graph})
- on each iteration, transfer the rank value from the source node to destination node, in proportion to the number of out-edges from the source node
Expressing how rank value P_r is transferred mathematically:
P_r(p_i) = \sum_{\text{edges}_{ji}} \frac{P_r(p_j)}{O_{j}}
where p represents the pages/nodes in our graph, i indexes over the destination nodes, j indexes over the source nodes, and O is a count of all the out-links from the j^{th} source node. We compute the above ratio and sum over all existing edges that run from j \rightarrow i.
Problems with the Simplified Approach
Let’s look again to the example presented in Figure 1. Nodes E and F represent problems for the simplified algorithm presented above. Node E is a sink, where it only has an input edge directed towards it. As a consequence, rank value will tend to to be lost at this node over successive iterations in the algorithm. Node F is a source node, with one outgoing connection to D. On the first iteration of the algorithm, the assigned rank value for F will be granted to node D, leaving F with a value of 0 for all further iterations.
This doesn’t seem to be sensible treatment for source or sink nodes. In addition, we are strictly limited to follow the edges in the graph, whereas in reality people surfing the web do not follow links all the time. Let’s make a more sophisticated algorithm, to handle more complex, and realistic, situations!
A More Sophisticated Approach: Introducing the Damping Factor
We can make a more realistic model by introducing a damping factor 0.0 \lt d \lt 1.0, that is the probability a user will follow a link on page p_j to page p_i. Typically d is set to 0.85. Conversely, 1-d is termed the fly-out probability, which is the chance a user will select a new page at random (i.e. will not follow an edge in the graph). With the inclusion of d, it is now possible to move past node E after landing on it, and it is possible to arrive back at F after leaving it.
Mathematically, we can include the damping factor in the following way:
P_r(p_i) = d\sum_{\text{edges}_{ji}} \frac{P_r(p_j)}{O_{j}} + \frac{1-d}{N_p}
where N_p is the total number of nodes (webpages) in the graph.
The Algorithm
We can now write out the algorithm for each iteration t=0,1,2,…:
1. Initialize the rank values for all pages P_r(p_i; t) in the graph at t=0 with: P_r(p_i; 0)=\frac{1}{N_p}
2. For t=1,2,3,… update the rank values with P_r(p_i;t+1) = d\sum_{\text{edges}_{ji}} \frac{P_r(p_j;t)}{O_{j}} + \frac{1-d}{N_p}
Let’s write things more compactly, by writing a matrix equation using the following objects:
{\bf P_r(t)} = \begin{bmatrix} P_r(p_0;t) \\ P_r(p_1;t) \\ \vdots \\ P_r(p_{N_p};t) \end{bmatrix} (1)
{\bf D} = \begin{bmatrix} 1/D_{0,0} && 0 && \cdots && 0 \\ 0 && 1/D_{1,1} && && \vdots \\ \vdots && && \ddots && \\ 0 && \cdots && && 1/D_{N_p,N_p} \end{bmatrix} (2)
{\bf O} = \begin{bmatrix} O_{0,0} && O_{0,1} && \cdots && O_{0,N_p} \\ O_{1,0} && O_{1,1} && && \vdots \\ \vdots && && \ddots && \\ O_{N_p,0} && \cdots && && O_{N_p,N_p} \end{bmatrix} (3)
{\bf \hat{O}} = {\bf OD} (4)
Here we have:
* {\bf P_r(t)} is a column vector containing all the page ranks at step t
* {\bf D} is a square diagonal matrix, where each element along the diagonal is either the inverse of the out-degree of node j, or 0.0 if there are no outgoing edges
* {\bf O} is the square adjacency matrix for the graph
* {\bf \hat{O}} is a modified form of the adjacency matrix, where each element \hat{O}_{i,j} is the ratio of edges from j \rightarrow i divided by the total out-degree of node j
* each column in {\bf \hat{O}} is normalized to sum to 1.0
Now we can rewrite the PageRank update at t+1 as:
{\bf P_r(t+1)} = d{\bf \hat{O}P_r(t)} + \frac{1-d}{N_p}{\bf 1} (5)
where the column vector {\bf 1} consists of N_p elements all set to 1.0.
We can continue updating until convergence is reached as set by \epsilon:
|{\bf P_r(t+1)} – {\bf P_r(t)}| < \epsilon (6)
In this way, we make use of the Power Iteration method, from linear algebra, to solve the PageRank problem.
Implement PageRank into Code
Let’s now work to implement the algorithm, described in the previous section, into Python code. We’ll start with importing the necessary packages:
import numpy as np
from typing import Tuple, ListI am going to work through the example graph illustrated in Figure 1 above. This graph can be described through its edges, recorded as a list of tuples (j,i):
edges = [("A","B"), ("B","D"), ("D","A"), ("D","C"), ("A","C"), ("C","A"), ("D","E"), ("F","D")]To start, let’s build a class called Graph that will handle all graph-related functionality:
class Graph(object):
def __init__(self, edges: List[Tuple]) -> None:
# initialize objects
nodes = set()
indegrees = {}
outdegrees = {}
# determine the unique set of nodes in the graph, and count number of outbound edges per source node
for edge in edges:
nodes.update(list(edge))
src, dst = edge
try:
outdegrees[src] += 1
except:
outdegrees[src] = 1
try:
indegrees[dst] += 1
except:
indegrees[dst] = 1
nodes = list(nodes)
nodes.sort()
# store graph data
self.edges = edges
self.nodes = nodes
self.number_nodes = len(nodes)
self.number_edges = len(edges)
self.indegrees = indegrees
self.outdegrees = outdegrees
def _build_adjacency_matrix(self) -> np.array:
# work out adjacency matrix
O = np.zeros((self.number_nodes,self.number_nodes))
for edge in self.edges:
src, dst = edge
O[self.nodes.index(dst),self.nodes.index(src)] += 1
return O
def _build_outdegree_matrix(self) -> np.array:
D = np.zeros((self.number_nodes,self.number_nodes))
for node in self.nodes:
try:
D[self.nodes.index(node),self.nodes.index(node)] = 1/self.outdegrees[node]
except:
D[self.nodes.index(node),self.nodes.index(node)] = 0
return D
def get_modified_adjacency_matrix(self) -> np.array:
return np.matmul(self._build_adjacency_matrix(),self._build_outdegree_matrix())
def get_edges(self) -> List[Tuple]:
return self.edges
def get_nodes(self) -> List:
return self.nodes
def get_number_edges(self) -> int:
return self.number_edges
def get_number_nodes(self) -> int:
return self.number_nodes
def get_indegrees(self) -> dict:
return self.indegrees
def get_outdegrees(self) -> dict:
return self.outdegreesThe member functions for this class include:
- __init__(self, edges) : the initializer function for the class, that takes a list of edges as input. This function computes the unique list of nodes in the graph, the total number of nodes and edges, and the in-degree and out-degree per node.
- _build_adjacency_matrix(self) : protected function that computes the adjacency matrix for the graph, as described by (3).
- _build_outdegree_matrix(self) : protected function that computes the diagonal matrix of inverse out-degrees per node, as described by (2).
- get_modified_adjacency_matrix(self) : member function to compute the matrix described by (4).
- get_edges(self) : returns the input list of edges.
- get_nodes(self) : returns the list of distinct nodes in the graph.
- get_number_edges(self) : returns the number of edges in the graph.
- get_number_nodes(self) : returns the number of nodes in the graph.
- get_outdegrees(self) : returns a dictionary containing the out-degree per node in the graph.
Now we can write a second class, PageRank, that will contain all the logic for the PageRank algorithm:
class PageRank(object):
def __init__(self, damping_factor: float=0.85, epsilon: float=1e-8) -> None:
self.damping_factor = damping_factor
self.epsilon = epsilon
def _initalize_pagerank(self, graph: Graph) -> np.array:
return (1/graph.get_number_nodes())*np.ones((graph.get_number_nodes(),1))
def _identity_vector(self, graph: Graph) -> np.array:
return np.ones((graph.get_number_nodes(),1))
def _step(self, P1: np.array, I: np.array, graph: Graph) -> np.array:
P2 = (
self.damping_factor*np.matmul(graph.get_modified_adjacency_matrix(),P1)
+ (1 - self.damping_factor)*I/graph.get_number_nodes()
)
return(P2/np.sum(P2))
def evaluate(self, graph: Graph) -> dict:
# obtain nodes from graph
nodes = graph.get_nodes()
# setup initial pagerank steps
P1 = self._initalize_pagerank(graph)
I = self._identity_vector(graph)
P2 = self._step(P1, I, graph)
# step through the algorithm, updating our pageranks
while(np.linalg.norm(P1 - P2) >= self.epsilon):
P1 = P2
P2 = self._step(P1, I, graph)
# package results and return
pageranks = {}
for node, rank in zip(nodes,P2.flatten()):
pageranks[node] = rank
return pageranksThis class consists of mostly protected functions, and one public function. These include:
- __init__(self, damping_factor, epsilon) : initializer for the class. Input arguments include the damping factor d, as well as epsilon: the threshold tolerance value \epsilon mentioned in (6).
- _initialize_pagerank(self, graph) : initializes the page rank values per node, at t=0.
- _identity_vector(self, graph) : returns the identity vector \bold{1} mentioned in (5).
- _step(self, P1, I, graph) : executes the update step at each iteration t in the algorithm, as described in (5).
- evaluate(self, graph) : the sole public function in this class. Here the PageRank algorithm is computed over the input Graph, and the resulting values are returned in a dictionary.
Running PageRank
We can now test out the classes implemented above. This involves setting up a graph, and then running the PageRank algorithm on it:
# create a graph object
graph = Graph(edges)
# create a pagerank object
pr = PageRank()
# compute pageranks
ranks = pr.evaluate(graph)
ranks{'A': 0.29526336887933935,
'B': 0.16277503210453523,
'C': 0.22454693557427846,
'D': 0.20155998078146667,
'E': 0.08881329306506174,
'F': 0.027041389595318478} These results seem sensible: the most interconnected nodes A, C, & D have the largest rank values. At the same time F, with no inbound links, has by far the lowest rank.
Let’s now double check our results, by comparing with the built-in PageRank from scikit-network.
import sknetwork as skn
from sknetwork.ranking import PageRank
graph = skn.data.from_edge_list(edges, directed=True)
adjacency = graph.adjacency
pagerank = PageRank()
scores = pagerank.fit_predict(adjacency)
scoresarray([0.24685275, 0.1374625 , 0.18928852, 0.17249258, 0.22754571,
0.02635795]) For the most part, the rankings here look very similar to those obtained with our custom implementation. Nodes A, C, and D are among the highest ranked in the graph, which makes sense as they have the most incoming edges. The biggest difference between the two sets of results is the page rank for node E, where this value is given more weight with the scikit-network model.
As mentioned previously, Node E is a sink, or otherwise termed a dangling node. The classic PageRank algorithm, presented here, has a hard time dealing with dangling nodes correctly. This fact is highlighted by the discrepancy between the two sets of values. Further alterations to the PageRank algorithm are required to handle nodes like E. In this video, I cover using PageRank on graphs with dangling nodes.
Final Remarks
In this post you have learned:
- What PageRank is, and why this algorithm was developed.
- The mathematics behind the PageRank algorithm.
- How to implement the PageRank algorithm into code.
I hope you enjoyed this article, and gained some value from it. If you would like to take a closer look at the code presented here, please take a look at my GitHub. If you have any questions or suggestions, please feel free to add a comment below. Your input is greatly appreciated.
Note I have started a New Monthly Newsletter! At the end of each month I will send out this free newsletter to each of my subscribers by email. This is the best way to stay on top of my latest content. Sign up for the newsletter here!
Related Posts
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.