Maximum Flow addresses the problem of finding the largest possible throughput between 2 nodes in a directed graph. In this post, we will first illustrate the concept of Maximum Flow, before properly defining the solution outlined in the Ford-Fulkerson – Edmonds-Karp algorithm. This algorithm will then be implemented into Python code, and tested on a small example. All code presented here can be found on my GitHub.
Table of Contents

Calculating Maximum Flow with 1 Simple Example – image by Abi Plata
What is Maximum Flow?
The problem of Maximum Flow (Max Flow) concerns the largest possible throughput between 2 nodes in a directed graph. In this scenario, each edge in the graph has a source and target node. All the edges have capacity limits, that restrict the throughput to a maximum amount. Figure 1 illustrates this setup below.
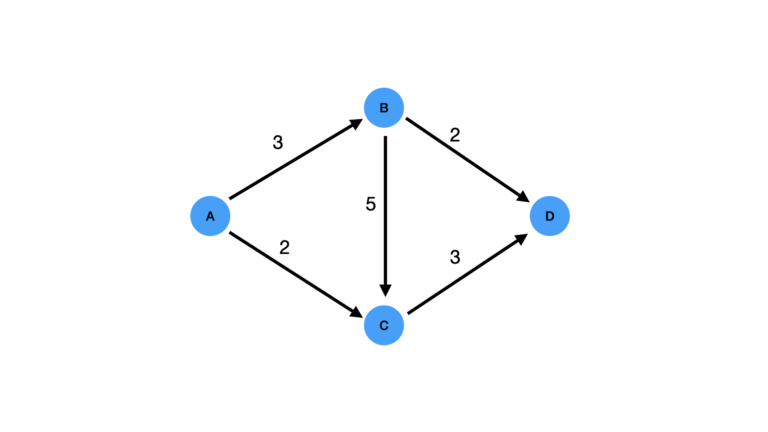
Figure 1: A simple directed graph with 4 nodes and 5 edges. Integers next to each edge represent the capacity limits. This example is based off of the one provided here.
An intuitive example would be to think of a series of pipes that carry water. These pipes connect with one another at junction points, and each pipe can have a different diameter. Here each pipe is an edge, and the junction points are nodes. The diameter of the pipe limits how much water can flow through it at any point in time, and therefore is analogous to the capacity limit for the edge.
Looking at Figure 1, we can see that nodes A, B, C, and D represent the junction points for edges A \rightarrow B, A \rightarrow C, B \rightarrow C, B \rightarrow D, and C \rightarrow D, which symbolize our pipes. We can now ask ourselves, how much water can possibly flow from A to D?
To answer this question, we need to find all possible paths through the graph that start at A, and end at D. For each path, we take note of the minimum capacity as the upper bound for what that path can carry. Here we can see that there are 3 paths: A \rightarrow B \rightarrow D, A \rightarrow C \rightarrow D, and A \rightarrow B \rightarrow C \rightarrow D. The first 2 paths each have a minimum capacity of 2. The third path technically has a minimum capacity of 3, however because of the flow already accounted for with the previous 2 paths, the amount of flow here is limited to 1. Summing these together, we see that the Max Flow for this example is 5.
Ford-Fulkerson - Edmonds-Karp Algorithm
Let’s now outline the algorithm we will use to compute Max Flow. I will be making use of the Ford-Fulkerson method with the Edmonds-Karp algorithm.
- Start with a directed graph, with each edge having a positive capacity C_{edge} value associated with it. I assume that there is only 1 edge going from source to target
- Prepare a residual graph: this involves adding new edges to the graph with reversed direction, and an initial capacity of 0
- Use BFS to identify a path through the residual graph from source to target, where the capacity for all edges involved is > 0
- Determine the minimum capacity C_{min} along the discovered path
- Update the residual graph in the following way:
- For all edges (source to target) in path update the capacity as follows: C_{edge} \leftarrow C_{edge} – C_{min}
- For all edges (target to source), update the capacity as follows: C_{edge} \leftarrow C_{edge} + C_{min}
- Go back to step 3 above, and repeat for as along as there is a viable path from source to target
Why a Residual Graph?
You might have noticed that the algorithm outlined above is somewhat more complicated than the simple example we walked through with Figure 1. In particular, the residual graph on step 2 should stand out. To outline why we go through the trouble of computing a residual graph, let’s extend our simple example by paying particular attention to the order with which we treat the different paths from A to D.
Now let’s imagine a scenario where the first path we look at is A \rightarrow B \rightarrow C \rightarrow D. The minimum capacity along this path is 3, and once we account for this our graph will look like the one in Figure 2.
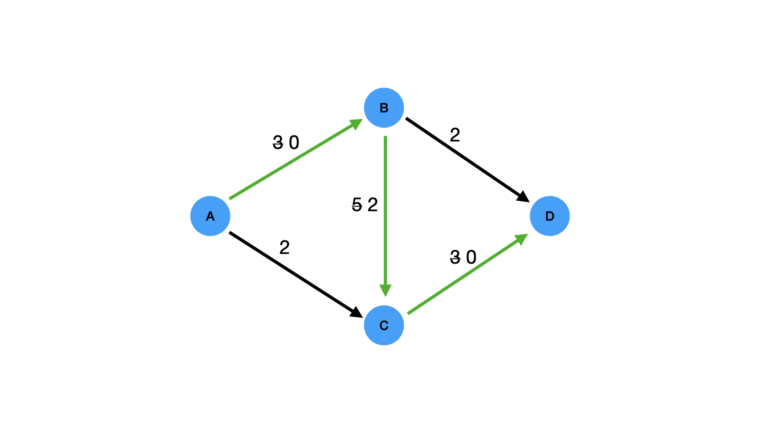
Figure 2: Effect of following path A \rightarrow B \rightarrow C \rightarrow D first through the graph. The path is highlighted in green, and remaining capacities along the affected edges are shown.
We can see, the updated capacities along edges A \rightarrow B and C \rightarrow D are now 0. As such, there is no longer any path that traverses from A to D where all the edges involved have some remaining capacity. Therefore, the algorithm would terminate with an incorrect value of 3 for the Max Flow.
The residual graph enables our algorithm to work regardless of the order of paths we analyse. To demonstrate this, let’s work through the above example again but include the residual graph.
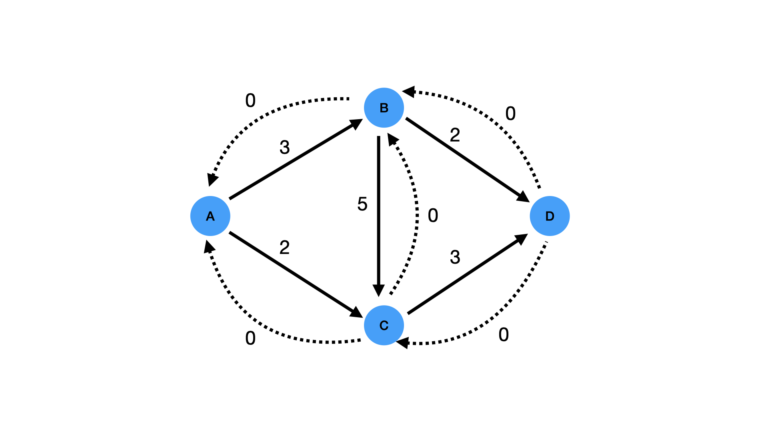
Figure 3: Residual graph added (dotted lines for new edges)
To build the residual graph, we add a new set of edges on top of those that are already present. One new edge is added for every existing edge in the example, with its direction reversed and an initial capacity of 0. This is illustrated in Figure 3 above.
Now let’s follow the Ford-Fulkerson – Edmonds-Karp algorithm. Again we’ll start by choosing the A \rightarrow B \rightarrow C \rightarrow D path, and update our graph according to step 5 of our procedure:
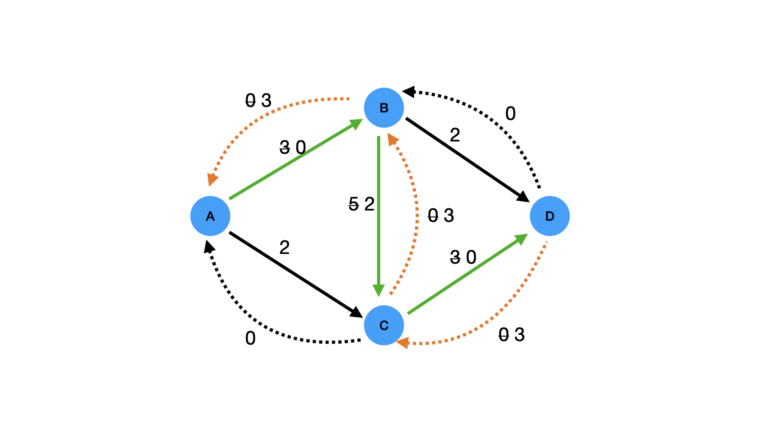
Figure 4: Effect of following path A \rightarrow B \rightarrow C \rightarrow D first through the residual graph. The path is shown in green, and the updated reversed edges are shown in orange.
Not only have we updated the capacities along the path, but we have also updated all the introduced reversed edges also. One of these is of particular importance to us: C \rightarrow B. Now we can see that this edge has an available capacity of 3! This therefore opens up the following pathway for us: A \rightarrow C \rightarrow B \rightarrow D.
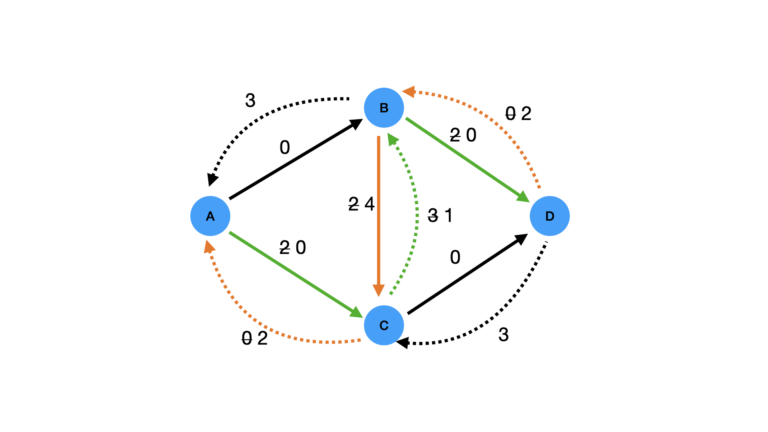
Figure 6: Effect of following path A \rightarrow C \rightarrow B \rightarrow D second through the residual graph. The path is shown in green, and the updated reversed edges are shown in orange.
The effects of following this second path are shown in Figure 6. This adds a further flow of 2 to node D. Since the first path contributed a flow of 3, this then sums to the correct value of 5.
Implement Maximum Flow in Python
We can now work through an implementation of Max Flow in Python. Let’s start by importing all the required packages:
import numpy as np
import pandas as pd
from typing import Tuple, ListI will now define a set of classes that will encapsulate much of the work we will need to do. The first, MaxFlowGraph, controls operations that directly affect the graph:
class MaxFlowGraph(object):
def __init__(self, edges: List[Tuple]) -> None:
self.edges = edges
nodes = set()
for edge in edges:
nodes.update(list(edge)[:-1])
self.nodes = list(nodes)
self.nodes.sort()
self.number_nodes = len(self.nodes)
self.reset_residual_graph()
def reset_residual_graph(self) -> None:
self.residual_graph = self.edges.copy()
count = len(self.residual_graph)
for i in range(count):
edge = self.residual_graph[i]
self.residual_graph.append((edge[1],edge[0],0,))
def get_adjacency_matrix(self) -> np.array:
# work out adjacency matrix
O = np.zeros((self.number_nodes, self.number_nodes))
for edge in self.residual_graph:
src, dst, capacity = edge
if capacity > 0:
O[self.nodes.index(dst),self.nodes.index(src)] = 1
return O
def compute_residual_capacity_on_edge(self, src: str, dst: str, reduction_amount: float) -> None:
# here I assume there is only 1 edge from src to dst
for i, edge in enumerate(self.residual_graph):
edge_src, edge_dst, edge_capacity = edge
if (src == edge_src) and (dst == edge_dst) and (edge_capacity > 0):
self.residual_graph[i] = (edge_src, edge_dst, edge_capacity - reduction_amount,)
elif (src == edge_dst) and (dst == edge_src):
self.residual_graph[i] = (edge_src, edge_dst, edge_capacity + reduction_amount,)- __init__(self, edges): initializer for a class instance
- reset_residual_graph(self): sets up a fresh residual graph (step 2 of our algorithm). This function is meant to be run before each Max Flow calculation
- get_adjacency_matrix(self): calculates and return the adjacency matrix for the residual graph
- compute_residual_capacity_on_edge(self, src, dot, reduction_amount): function to update the edge src \rightarrow dst that lies along the path found, as well as its mirror opposite edge dst \rightarrow src. This is step 5 in our algorithm
We can now define a class that will handle the graph traversal:
class BFS(object):
def __init__(self, graph: MaxFlowGraph) -> None:
self.graph = graph
def _prepare_for_traversal(self, source: str) -> None:
self.queue = [source]
self.visited = dict(zip(self.graph.nodes, len(self.graph.nodes) * [False]))
self.visited[source] = True
def _process_unvisited_neighbours(self, node: str) -> None:
node_index = self.graph.nodes.index(node)
neighbours_indices = self.graph.get_adjacency_matrix()[:,node_index].nonzero()[0].tolist()
neighbours = np.array(self.graph.nodes)[neighbours_indices].tolist()
for neighbour in neighbours:
if not self.visited[neighbour]:
self.queue.append(neighbour)
self.visited[neighbour] = True
def traverse(self, source: str) -> None:
# prepare for the traversal
self._prepare_for_traversal(source)
# process queue
while self.queue:
# pop a node from the queue
node = self.queue.pop(0)
# go to each unvisited neighbour of node
self._process_unvisited_neighbours(node)Note that this class is closely based off the one I implemented in my Breadth-First Search post. Please refer to that article for a detailed explanation for how BFS works.
I will now build upon BFS, to implement a class that can return paths through the graph:
class Path(object):
def __init__(self, label: str):
self.label = label
self.next_level = []
class PathFinder(BFS):
def _add_to_paths(self, paths: Path, node: str, neighbour: str) -> None:
if paths.label == node:
paths.next_level.append(Path(neighbour))
elif (paths.label != node) and paths.next_level:
for path in paths.next_level:
self._add_to_paths(path, node, neighbour)
def _process_unvisited_neighbours(self, node: str) -> None:
node_index = self.graph.nodes.index(node)
neighbours_indices = self.graph.get_adjacency_matrix()[:,node_index].nonzero()[0].tolist()
neighbours = np.array(self.graph.nodes)[neighbours_indices].tolist()
for neighbour in neighbours:
if not self.visited[neighbour]:
self.queue.append(neighbour)
self.visited[neighbour] = True
self._add_to_paths(self.paths, node, neighbour)
def _determine_shortest_path(self, paths: Path, target: str, path_string: str) -> None:
if paths.label == target:
self.shortest_path = path_string + target
elif paths.next_level:
for path in paths.next_level:
self._determine_shortest_path(path, target, path_string + paths.label)
def find_shortest_path(self, source: str, target: str) -> bool:
# initialize path string
self.shortest_path = ""
# define a Path instance to store all possible paths from source
self.paths = Path(source)
# traverse graph
self.traverse(source)
# identify shortest path that terminates at target
self._determine_shortest_path(self.paths, target, self.shortest_path)
# return status
if self.shortest_path:
return True
return FalsePathFinder is another class that is very close to one with the same namesake in my previous post on BFS. Please refer to that article for a detailed outline for how this class works. For the present discussion it’s important to highlight:
- _process_unvisited_neighbours(self, node): this function is overwrites the one with the same name in BFS
- find_shortest_path(self, source, target): uses BFS to find a path from source to target where all edge capacities involved are > 0. This is step 3 of our algorithm
Now we can finally put together a function that can compute Max Flow:
# iterate over all possible paths, compute max flow
def maxflow(pf: PathFinder, src: str, dst: str) -> float:
maxflow = 0
while pf.find_shortest_path(src, dst):
# prepare path
path = pf.shortest_path
path = list(path)
# get minimum capacity along path
dfEdges = pd.DataFrame(pf.graph.residual_graph, columns=['src', 'dst', 'capacity'])
min_capacity = float('inf')
for i in range(len(path)-1):
row = dfEdges[(dfEdges.src == path[i]) & (dfEdges.dst == path[i+1])]
if row.capacity.values[0] < min_capacity:
min_capacity = row.capacity.values[0]
# max flow
maxflow += min_capacity
# compute residual graph
for i in range(len(path)-1):
pf.graph.compute_residual_capacity_on_edge(path[i], path[i+1], min_capacity)
return maxflowThe function maxflow takes in a PathFinder object, along with the labels of the source src and target dst nodes we wish to do the computation for.
Test the Implementation
Now we can make use of the classes already defined to test out a calculation of Max Flow. Let’s create a list of edges that represent the same graph as is illustrated in Figure 1:
edges = [("A", "B", 3),("B", "D", 2),("A", "C", 2),("B", "C", 5),("C", "D", 3)]Note that edges is a list of tuples, with each tuple consisting of: (source, target, capacity).
We can create an instance of a MaxFlowGraph, which should automatically setup the residual graph:
# create a graph instance
graph = MaxFlowGraph(edges)
# view initial residual graph
graph.residual_graph[('A', 'B', 3),
('B', 'D', 2),
('A', 'C', 2),
('B', 'C', 5),
('C', 'D', 3),
('B', 'A', 0),
('D', 'B', 0),
('C', 'A', 0),
('C', 'B', 0),
('D', 'C', 0)] We can see that the initializer has already created a residual graph, with all the reverse edges having a capacity of 0.
Let’s check to see that our instance has correctly identified the nodes, and setup the adjacency matrix:
# view detected nodes
graph.nodes['A', 'B', 'C', 'D']
# view initial adjacency matrix
graph.get_adjacency_matrix()array([[0., 0., 0., 0.],
[1., 0., 0., 0.],
[1., 1., 0., 0.],
[0., 1., 1., 0.]]) Both of these look good. Note that for the adjacency matrix, the columns represent the source nodes (in the same order as the graph.nodes list), while the rows are the target nodes. Elements within this matrix will only be set to 1 if there is capacity available at that edge.
Now for the real test: let’s create a PathFinder instance, and then attempt to compute the Max Flow from A to D:
# create a PathFinder instance
pf = PathFinder(graph)
# compute maxflow
maxflow(pf, 'A', 'D')5
This is the correct answer! Now how have the residual graph and adjacency matrix been modified?
# view final residual graph
graph.residual_graph[('A', 'B', 0),
('B', 'D', 0),
('A', 'C', 0),
('B', 'C', 4),
('C', 'D', 0),
('B', 'A', 3),
('D', 'B', 2),
('C', 'A', 2),
('C', 'B', 1),
('D', 'C', 3)] # view final adjacency matrix
graph.get_adjacency_matrix()array([[0., 1., 1., 0.],
[0., 0., 1., 1.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]) We can see that both have been updated, as we would expect from an execution of this algorithm.
Final Remarks
In this post you have learned:
- What is Maximum Flow (Max Flow)
- What the Ford-Fulkerson – Edmonds-Karp algorithm is, and why it was developed
- How to implement Max Flow from scratch in Python
I hope you enjoyed this article, and gained some value from it. If you would like to take a closer look at the code presented here, please take a look at my GitHub. If you have any questions or suggestions, please feel free to add a comment below. Your input is greatly appreciated.
Note I have started a New Monthly Newsletter! At the end of each month I will send out this free newsletter to each of my subscribers by email. This is the best way to stay on top of my latest content. Sign up for the newsletter here!
Related Posts
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.