In this article, we will cover Breadth First Search (BFS). This algorithm describes a procedure for traversing both undirected and directed graphs. I will first describe the BFS algorithm, before implementing it into Python code in a Jupyter notebook. We will test out this implementation on a toy graph dataset, to verify everything works. All code presented here can be found on my GitHub.
Table of Contents

Graph Traversal – The BFS Algorithm – image by author
What is the BFS Algorithm?
The BFS algorithm is a technique for traversing a graph, given a starting node from which to begin. The general strategy is to explore all possible neighbouring nodes that are the same number of “hops”, or edges, away from the starting node. This is done before looking at nodes that are more distant from the starting node. BFS was first published in 1959 by Edward F. Moore: “The shortest path through a maze“. Proceedings of the International Symposium on the Theory of Switching. Harvard University Press. pp. 285–292.
One consideration we need to keep in mind is the presence of cycles in the graph: this could lead to an infinite traversal if not accounted for. As such, we know right away that we will need to keep track of the nodes already visited, while passing through the graph.
BFS is executed in the following fashion:
- Initialize by creating a queue object q and enter the starting node s into this queue. Also mark all nodes in the graph as “not visited”
- While q is not empty:
- Pop a node n from q, and perform whatever calculations are needed at that node
- For each unvisited neighbour of n:
- Add the neighbour into q
- Mark the neighbour as visited
There are various applications for the BFS algorithm, some examples of which include:
- Finding paths between nodes in a graph
- Identifying connections between components in a graph
- Calculating max-flow between sets of source and target nodes
- Solving shortest path problems
BFS Algorithm - Step by Step
Let’s work through the algorithm described above, by visualizing each step. To start, we can look at the example graph we will work with:
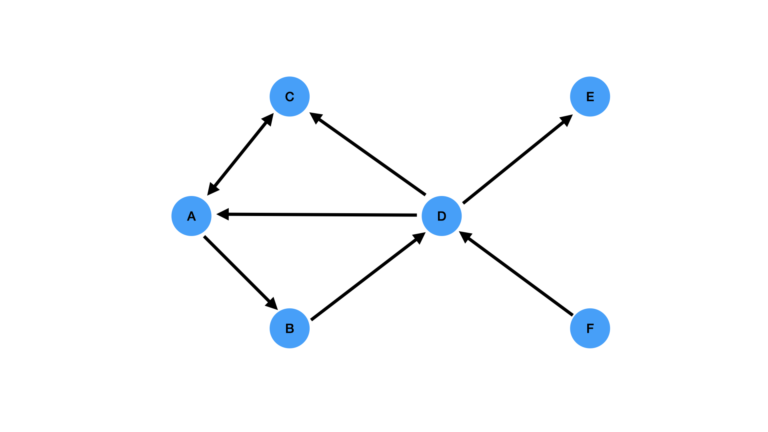
Figure 1: Toy directed graph with nodes labeled A through F.
Figure 1 illustrates the directed graph we will work with. Note this is the same graph we’ve looked at in my previous article on PageRank.
Now we start by selecting our starting node. In this particular case, we will select node A:
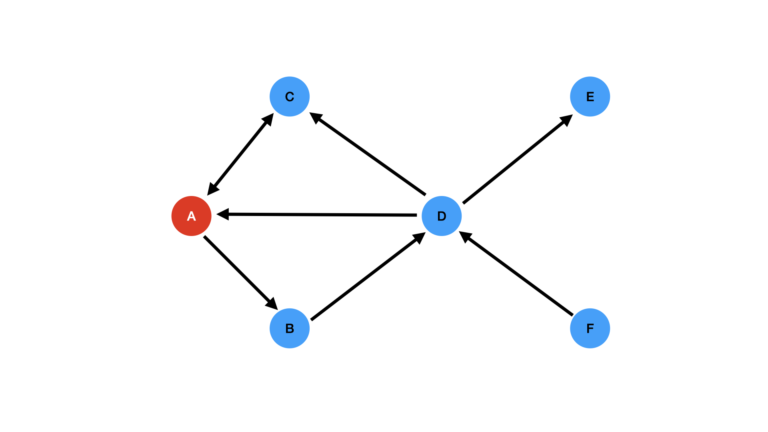
Figure 2: Starting node A indicated in red.
Node A is now colored red, to illustrate that this node has now been visited. The next step in the algorithm is to visit the neighbours of A:
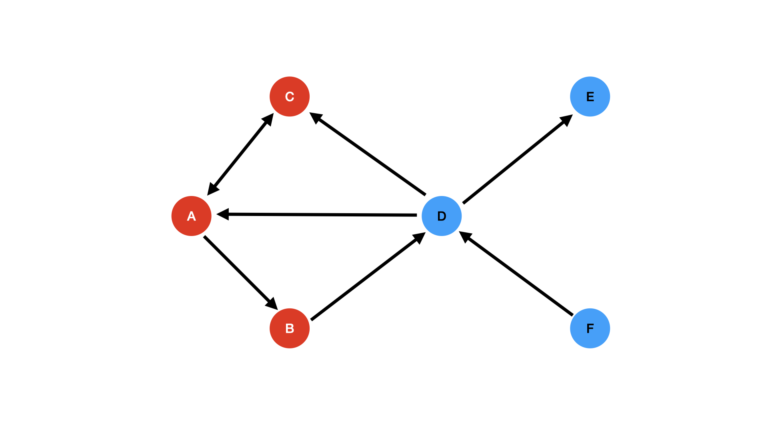
Figure 3: Neighbours of A now visited.
Figure 3 now shows nodes A, B, and C all colored red, indicating these nodes are visited. Note that despite having an edge with A, node D has not been visited. This is because this edge runs from D to A.
Next we visit the neighbours of B and C:
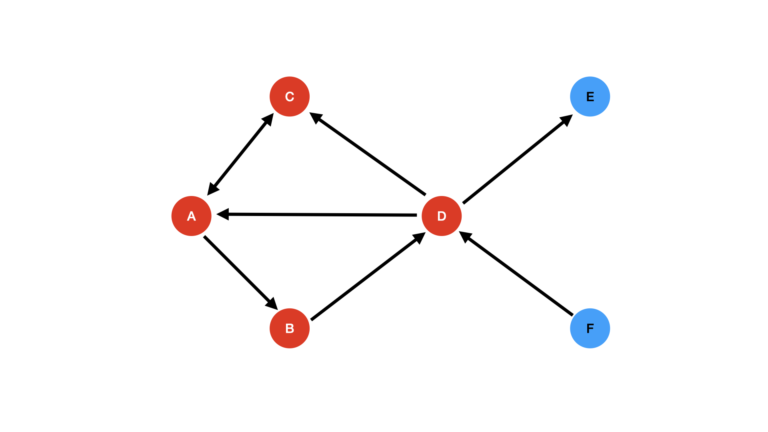
Figure 4: Neighbours of B and C now visited.
Node D has now been visited. Note that we reached D through B: node C has no outgoing edges to unvisited nodes.
Let’s now visit the neighbours of D:
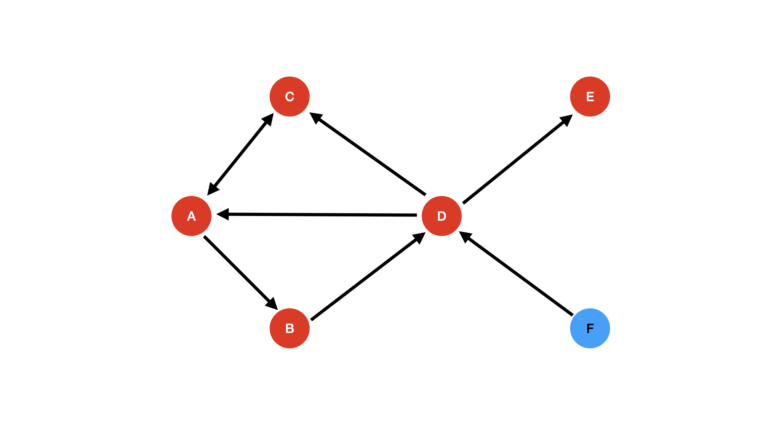
Figure 5: Neighbours of D now visited.
We now have visited node E. The algorithm terminates here, as all reachable nodes have been visited. As such, node F remains unvisited. Since F is a pure source node, the only way to visit this node is by selecting it as the starting position.
Implement BFS in Python
Let’s now proceed to implement BFS into Python code. We can start by importing the packages required:
from typing import List
import numpy as npTo avoid duplicate effort, I’ll run the notebook created for the post on PageRank. This will import the edge and Graph objects defined in that notebook:
%run Notebook\ XXIX\ Learn\ the\ PageRank\ Algorithm\ with\ 1\ Simple\ Example.ipynbWe can check to see that the edges are now available:
edges[('A', 'B'),
('B', 'D'),
('D', 'A'),
('D', 'C'),
('A', 'C'),
('C', 'A'),
('D', 'E'),
('F', 'D')] The edges define the graph illustrated in Figures 1 – 5, where each tuple defines a directed edge as: (source, target).
Our implementation of BFS will be encapsulated into a single class. Let’s take care of that now:
class BFS(object):
def __init__(self, graph: Graph) -> None:
self.graph = graph
def _prepare_for_traversal(self, source: str) -> None:
self.queue = [source]
self.visited = dict(zip(self.graph.nodes, len(self.graph.nodes) * [False]))
self.visited[source] = True
def _computations_on_node(self, node: str) -> None:
print(f"Processing node {node}")
def _process_unvisited_neighbours(self, node: str) -> None:
node_index = self.graph.nodes.index(node)
neighbours_indices = self.graph.get_modified_adjacency_matrix()[:,node_index].nonzero()[0].tolist()
neighbours = np.array(self.graph.nodes)[neighbours_indices].tolist()
for neighbour in neighbours:
if not self.visited[neighbour]:
self.queue.append(neighbour)
self.visited[neighbour] = True
def traverse(self, source: str) -> None:
# prepare for the traversal
self._prepare_for_traversal(source)
# process queue
while self.queue:
# pop a node from the queue, and perform desired actions on the node
node = self.queue.pop(0)
self._computations_on_node(node)
# go to each unvisited neighbour of node
self._process_unvisited_neighbours(node)- __init__(self, graph): initializer for BFS, that takes as input a Graph object.
- _prepare_for_traversal(self, source): prepares the instance for execution of the algorithm. This is the first step in BFS.
- _computations_on_node(self, node): any calculations that need to be done on a specific node are done here. These are executed when a node n is popped from the queue q.
- _process_unvisited_neighbours(self, node): processing of all unvisited neighbours of node n is done here. Neighbours are identified through the modified adjacency matrix provided by Graph.
- traverse(self, source): primary function to orchestrate the execution of the algorithm, given the starting node source.
We can test out our implementation by first creating an instance of Graph, and then declaring an instance of BFS:
# create a graph instance
graph = Graph(edges)
# create a BFS instance
bfs = BFS(graph)We can experiement with a few different source node choices:
bfs.traverse('A')Processing node A Processing node B Processing node C Processing node D Processing node E
bfs.traverse('D')Processing node D Processing node A Processing node C Processing node E Processing node B
bfs.traverse('F')Processing node F Processing node D Processing node A Processing node C Processing node E Processing node B
It appears our implementation is working as expected! The order of the printout indicates at what step a node is popped from the queue q. Note that node F only appears in our results when it is set as a source node. This makes sense as we are working with a directed graph, and F has no incoming edges.
A Tangible Example: Find Shortest Path
To make things more concrete, let’s build a practical application with BFS. In this instance, we can build a class PathFinder that will inherit from BFS. The aim of this new class will be to find the shortest path between two nodes. Let’s go over this implementation now:
class Path(object):
def __init__(self, label: str):
self.label = label
self.next_level = []
class PathFinder(BFS):
def _add_to_paths(self, paths: Path, node: str, neighbour: str) -> None:
if paths.label == node:
paths.next_level.append(Path(neighbour))
elif (paths.label != node) and paths.next_level:
for path in paths.next_level:
self._add_to_paths(path, node, neighbour)
def _process_unvisited_neighbours(self, node: str) -> None:
node_index = self.graph.nodes.index(node)
neighbours_indices = self.graph.get_modified_adjacency_matrix()[:,node_index].nonzero()[0].tolist()
neighbours = np.array(self.graph.nodes)[neighbours_indices].tolist()
for neighbour in neighbours:
if not self.visited[neighbour]:
self.queue.append(neighbour)
self.visited[neighbour] = True
self._add_to_paths(self.paths, node, neighbour)
def _determine_shortest_path(self, paths: Path, target: str, path_string: str) -> None:
if paths.label == target:
self.shortest_path = path_string + target
elif paths.next_level:
for path in paths.next_level:
self._determine_shortest_path(path, target, path_string + paths.label)
def find_shortest_path(self, source: str, target: str) -> str:
# initialize path string
self.shortest_path = ""
# define a Path instance to store all possible paths from source
self.paths = Path(source)
# traverse graph
self.traverse(source)
# identify shortest path that terminates at target
self._determine_shortest_path(self.paths, target, self.shortest_path)
# return shortest path
return self.shortest_path- The class Path is used when assembling the different possible ways to traverse the graph. It maps a node with label, that has outgoing edges pointing towards other nodes listed in next_level.
- _add_to_paths(self, paths, node, neighbour): the logic in this recursive function is used to build the various paths through the graph.
- _process_unvisited_neighbours(self, node): this function is overwritten from BFS. Here we augment the original function with a call to _add_to_paths().
- _determine_shortest_path(self, paths, target, path_string): this recursive function is used to determine the shortest path to target, based on the input paths object.
- find_shortest_path(self, source, target): primary function to orchestrate finding the shortest path from source to target.
Let’s try out our new class, to see how it works with some examples:
# create a PathFinder instance
pf = PathFinder(graph)
pf.find_shortest_path('F','E')Processing node F Processing node D Processing node A Processing node C Processing node E Processing node B
'FDE'
pf.find_shortest_path('A','F')Processing node A Processing node B Processing node C Processing node D Processing node E
''
pf.find_shortest_path('A','E')Processing node A Processing node B Processing node C Processing node D Processing node E
'ABDE'
It is apparent that our new class PathFinder is able to map out the shortest path between two nodes in our directed graph, if such a path exists.
Final Remarks
In this post you have learned:
- What the Breadth First Search (BFS) algorithm is, and why this was developed.
- How to implement BFS into Python.
- How to apply BFS to the problem of finding the shortest path between two nodes in a directed graph.
I hope you enjoyed this article, and gained some value from it. If you would like to take a closer look at the code presented here, please take a look at my GitHub. If you have any questions or suggestions, please feel free to add a comment below. Your input is greatly appreciated.
Note I have started a New Monthly Newsletter! At the end of each month I will send out this free newsletter to each of my subscribers by email. This is the best way to stay on top of my latest content. Sign up for the newsletter here!
Related Posts
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.