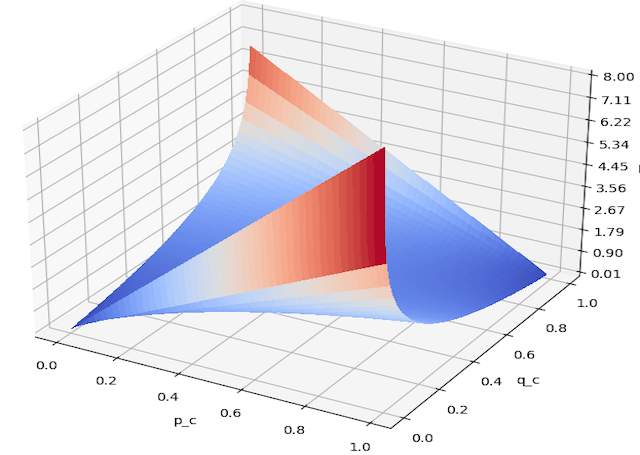
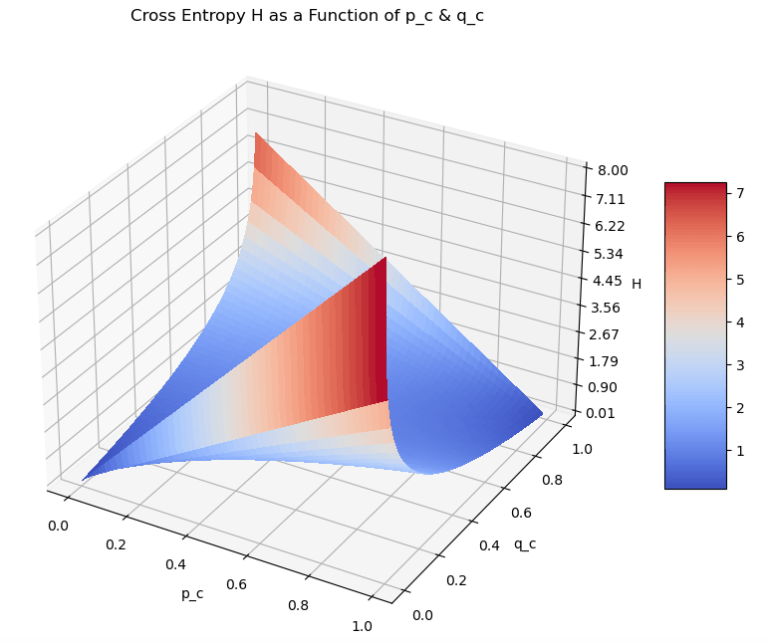
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Hi I'm Michael Attard, a Data Scientist with a background in Astrophysics. I enjoy helping others on their journey to learn more about machine learning, and how it can be applied in industry.
Why log to the base 2 ?
This comes from the definition of the Shannon entropy, which also used log base 2. In information theory, using log base 2 forms the definition of a bit. Alternatively, if we were to use log base e, then the entropy would be measured in nats.